
线性分类(Linear Classification)
我们将要实现一种更强大的方法来解决图像分类问题,该方法可以自然地延伸到神经网络和卷积神经网络上。这种方法主要有两部分组成:一个是评分函数(score function),它是原始图像数据到类别分值的映射。另一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
评分函数
线性分类的第一个部分就是一个评分函数, 用于将输入的图像转换为各个分类上的评分.
$$
f(x,W)
$$
x是输入的图片拉伸出的D维列向量([D*1]), 分类共有N个, W是经过训练计算出的参数(权重), 是一个[N*D]的矩阵. 那么, 计算出的$f(x,W)$就会是一个N维列向量([N*1]), 向量的每一个分量就是每一个分类的评分.
假设x为一个2*2的图像, 拉伸后的向量为(11,2,13,24), 选择 $f(x,W)=x*W$ , 作为评分函数.
1 | import numpy as np |
线性分类器
$$
f(x,W)=x*W
$$
上面的函数就是一个最简单的线性分类器, 我们为这个函数加上一个偏差向量b, 体现我们对某一类的偏好值.
最终, 函数变成了这种形式:
$$
f(x,W)=x*W+b
$$
这就是一个最简单的线性分类器了.
对线性分类器的理解
模板匹配
可以看出, 每一个类的分类, 与W中的每一个行向量有关, 我们可以将每一个行向量还原为图像, 就得到了每一个类的模板. 那么我们的分类器所做的, 就是通过向量点乘的方法, 将待测图片与每个模板进行比较, 并对比较的结果评分, 找到与哪个模板最相似.
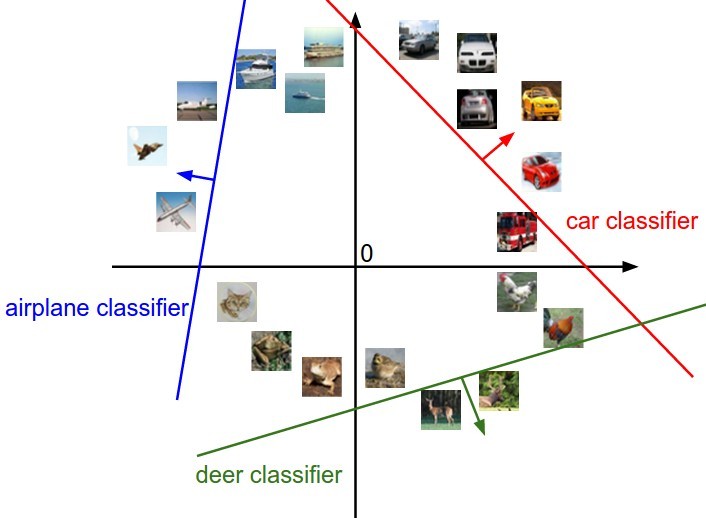
高维空间的线性决策
每一张图像都是一个D维列向量, 我们可以把它当成是一个高维空间上的点, 分类器的任务, 就是在这个高维空间中画出一个线性的分类面, 将一块空间划分为一个类和其他的类两个部分.
损失函数
在评分函数中, 我们需要设定一个W来对图像进行分类, 那么如何选出一个W, 使得评分函数在正确的分类上有最高的评分(也就是选对分类). 于是, 我们又要引入一个函数来量化评价一个W的好坏, 这个函数就是损失函数.
损失函数(Loss Function)(有时也叫代价函数Cost Function或目标函数Objective)衡量我们对结果的不满意程度。直观地讲,当评分函数输出结果与真实结果之间差异越大,损失函数输出越大,反之越小。
损失函数的形式
数据集:
$$
{(x_i,y_i)}^N_{i=1}
$$
损失函数为:
$$
L={1 \over N}\sum_i L_i(f(x_i,W),y_i)
$$
多类别支持向量机损失函数(Multiclass Support Vector Machine Loss)
$$
L_i=\sum_{j\neq y_i} \max(0,S_j-S_{y_i}+\Delta)
$$
$\Delta$为安全边距(Safety margin), 可以设为1, 不影响结果.
也就是说当评分函数 (在正确分类上的评分-在错误分类上的评分)>$\Delta$, 函数在这个分类上的损失为0, 也可以说这是一个折页损失函数.
正则化(Regularization)
假设有一个数据集和一个权重集W能够正确地分类每个数据(即所有的边界都满足,对于所有的i都有 $L_i=0$ )。问题在于这个W并不唯一:可能有很多相似的W都能正确地分类所有的数据。一个简单的例子:如果W能够正确分类所有数据,即对于每个数据,损失值都是0。那么当 $\lambda>1$ 时,任何数乘 $\lambda W$ 都能使得损失值为0,因为这个变化将所有分值的大小都均等地扩大了,所以它们之间的绝对差值也扩大了。
为了防止W的项过大或过于复杂, 我们要对W增加一点偏好, 使得它不向着更复杂的方向发展, 造成过拟合. 于是, 我们又对损失函数添加一个正则化惩罚 $\lambda R(W)$ , $\lambda$为一个超参数, 用于衡量惩罚的力度(正则化的强度) .
最常用的是L2范式, 对W中的每个元素先平方后求和:
$$
R(W)=\sum_k\sum_l(W_{k,l})^2
$$
加上这个惩罚项, 我们得到了完整的多类别SVM函数, 它包含一个数据损失和一个正则化损失:
$$
L={1 \over N}\sum_i L_i(f(x_i,W),y_i)+\lambda R(W)
$$
Softmax分类器
Softmax的输出(归一化的分类概率)更加直观,并且从概率上可以解释。在Softmax分类器中,函数映射f保持不变,但将这些评分值视为每个分类的未归一化的对数概率,并且将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)。
公式如下:
$$
P(Y=y_i|x=x_i)=\frac {e^{f_{y_i} } } {\sum_j e^{f_j} }
$$
$P(Y=y_i|x=x_i)$在这里表示以 $x_i$ 为输入, 以W为参数选中正确标签 $y_i$ 的概率.
我们选择一个函数$L_i=-\log P$对P进行处理, 得到$L_i$的公式. 最终使这个损失函数取值为$(0,+\infty)$ .
$$
L_i=-\log(\frac {e^{f_{y_i} } } {\sum_j e^{f_j} })
$$